

Unpacking AI's Potential and Impact
As the dust starts to settle — speculating about where AI will land and what that means for investors

Intro: Unpacking the AI narrative and where it stands
Like any good mania, the AI frenzy that kicked off with the public launch of Chat-GPT, is based on a narrative that achieves near perfect “Goldie Locks complexity.” It’s just digestible enough for main street to buy in, yet sufficiently opaque that sellers (and true believers) can project any outcome they like onto it. And certainly those projections ran their course in 2023.
It seems most prognosticators are suggesting that we are currently at “peak OpenAI” — that the narrative is fully baked and we can only fall short of lofty expectations from here. I tend to agree, but I think some market participants can actually exceed expectations if they are willing to accept the current state of AI’s limitations and focus more on productizing and less on core model development. To put it a different way, the value from here lays in shifting from basic R&D to translational R&D or even more basic “internal IT modernization”.
Admittedly, I am talking my own book a bit here as someone who runs a technology consultancy, but my sincere belief is that from here on out, value will accrue in technology orgs that effectively apply these rapidly commoditizing models to actual business problems. I’ll toss out some ideas related to specific public companies towards the end of this piece.
Back to hype vs. reality. Just a few months ago Sundar Pichai wrote that AI may end up bigger than the internet itself. As a reasoning aid, I thought it would be interesting to evaluate how today’s AI feels compared to other shifts that have proven to be themselves transformative.
I’m of an age (but just barely) that I still remember using Dog Pile and Ask Jeeves prior to Google coming on the scene. While my use case of researching the Clone Wars with my babysitter Nathanial (whose name I pronounced “Napanial”) certainly was not complex, I do recollect the “magic” of watching the information of the universe materialize in mere moments during those first Google searches. Similarly, if I think about the first iPhone or when we started to deploy applications to AWS, I still can access that feeling of awe I felt during the first few times I worked with something destined to be a web scale (i.e. global) platform.
Working with today’s AI tools, I feel that this is cool, interesting, and cute, but I don’t feel that I am holding magic in my hands.
This feels more like “spreadsheets” than Google
When I write AI here, I am reluctantly accepting the overwhelming popular definition to mean the large transformer based models (including LLM’s) that more often than not have some kind of natural language interface.
AI by this definition, strikes me as closer to the introduction of spreadsheets than mobile, cloud, social, or the web itself.
Some folks, however, who have far more resources, experience, and information than I do, like David Sacks, for example, are saying something else, that AI is the next great platform — and he isn’t just talking, he explicitly said that he and his team are spending 70%-80% of their time looking at AI which I can assume translates roughly to where his dollars under management are headed as well.
So who is right and where are we headed? I think it’s useful to look at the history of AI development, investment and hype. I encourage you to give this 2018 Actuaries Digital piece a read. It includes this helpful graphic illustrating prior AI boom and bust cycles:
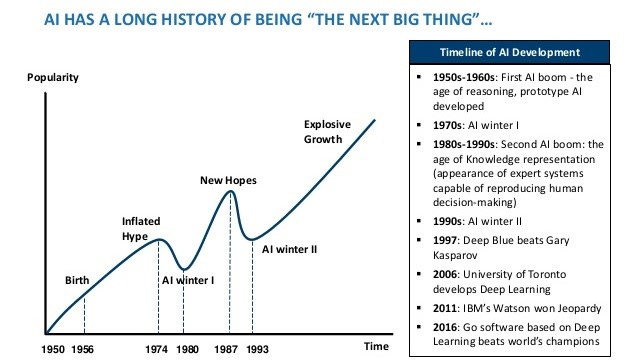
I would generally consider the transformer driven boom we are seeing right now to be a continuation of the large compute enabled rising tide of neural network based models.
Maybe Sacks and I are both correct — that AI today is not magic, will be consistently pervasive but not instantaneously transformative, and generally will have impact similar to that of spreadsheets. And by the way, I think by many definitions, you could comfortably define spreadsheets as a platform. This feels appropriate to me and an apt comparison to AI today as just like spreadsheet GUI’s made huge computing power available to non-programmers (and programmers!), natural language chat interfaces are doing the same thing today for even more people. That said, I am able to think of a handful but not many “spreadsheet” products or companies that were hugely successful. From that perspective, I don’t know if it’s really appropriate for a VC to invest 80% of capital there.
But hey, they are cool:
This section of this post was written in the Chat-GPT GUI.
Me:
Could you please write me a summary of the history of spreadsheets? Specifically the summary should include the following: when the first spreadsheets were introduced, which companies and products were the largest commercial winners in the space, and some estimation of what fraction of the world's computation today takes place via spreadsheets.
ChatGPT:
The history of spreadsheets traces back to the late 1970s when the first electronic spreadsheet, VisiCalc, was introduced in 1979. Developed by Dan Bricklin and Bob Frankston, VisiCalc ran on the Apple II computer and marked a significant departure from traditional manual methods of data management.
In the early 1980s, Lotus 1-2-3 became a major player in the spreadsheet market. Developed by Lotus Development Corporation, it integrated spreadsheet, charting, and database capabilities, making it highly popular among businesses. Lotus 1-2-3 dominated the market until the late 1980s.
Microsoft Excel, introduced in 1985, emerged as a formidable competitor to Lotus 1-2-3. With its intuitive interface and integration with other Microsoft Office applications, Excel eventually surpassed Lotus 1-2-3 in popularity. Microsoft Excel continues to be a leading spreadsheet software and a standard tool for data analysis and management.
As for the commercial winners, Microsoft Excel is undoubtedly one of the largest winners, dominating the market for several decades. Lotus 1-2-3 had its heyday but eventually faded, while other competitors like Quattro Pro and Google Sheets have also made significant contributions.
Estimating the fraction of the world's computation happening via spreadsheets is challenging, but it's safe to say that spreadsheets play a crucial role in a wide range of industries. They are extensively used for financial modeling, data analysis, project management, and more. However, with the rise of advanced analytics tools, databases, and cloud computing, the role of spreadsheets has evolved, and their share in overall computation is just one facet of the broader computational landscape.
Me:
Are there any parallels between the proliferation of spreadsheets and large language models?
ChatGPT:
Yes, there are some parallels between the proliferation of spreadsheets and large language models. Both represent significant advancements in technology that have had a profound impact on how people work with and analyze information.
Democratization of Tools: Both spreadsheets and large language models contribute to the democratization of tools for data manipulation and analysis. Spreadsheets made it easier for individuals with varying levels of technical expertise to perform calculations and organize data. Similarly, large language models, like GPT-3, enable users to generate human-like text and engage in natural language processing without extensive programming knowledge.
Productivity Enhancement: Spreadsheets and large language models enhance productivity by automating tasks that were once manual and time-consuming. Spreadsheets automate calculations and data organization, while language models automate the generation of coherent and contextually relevant text, reducing the effort required for content creation.
Ubiquitous Adoption: Both spreadsheets and large language models have achieved widespread adoption across various industries. Spreadsheets are a standard tool in business, finance, and academia, while large language models are increasingly used in natural language understanding, content generation, and other applications across different domains.
Evolution and Innovation: Both technologies have evolved over time to meet changing needs and incorporate new features. Spreadsheets have gone from basic grids for calculations to sophisticated tools with advanced functions, charts, and collaborative features. Similarly, large language models have evolved to handle more complex language tasks and adapt to a wide range of applications, from chatbots to content generation.
Impact on Workflows: Spreadsheets and large language models have impacted how work is done. Spreadsheets streamlined data-related tasks and financial modeling, while large language models have the potential to transform how we interact with and generate textual content, influencing content creation and communication workflows.
While there are parallels, it's important to note that spreadsheets and large language models operate in different domains, addressing distinct needs. Spreadsheets are primarily focused on numerical and tabular data, while large language models excel in understanding and generating human-like text.
Me
I see what you did there with your use of the word "excel"
ChatGPT
Ah, I'm glad you caught that! It seems my pun didn't go unnoticed. Wordplay is always a fun way to inject a bit of humor into the conversation. If you have any more questions or if there's anything else you'd like to explore, feel free to let me know!
That was fun, but again, I’d call it fun, not magic.
What can the underlying tech tell us?
Back in 2014 I followed Michael Nielsen’s Neural Networks and Deep Learning book which he was publishing chapter by chapter at the time. I implemented a neural network from scratch that could read the handwritten digits of 0-9.
That experience impacted me profoundly and caused me to deeply question the nature of cognition and knowledge. My program took in an image file of a written digit and broke it into a matrix of dots. It then quantified the “darkness” of each dot and thereby produced a structured input for the neural network to process.
The neural network itself processed those inputs and spit out an array of values each of which corresponded to the digits 0-9. Whichever value came out the strongest was thus the program’s guess at which number it was.
To train the network, I had implemented a gradient descent algorithm which manually computed how the program’s internal weighting should have been updated in order to make its guess less wrong. It did that by computing the partial derivative of each internal parameter and then combining those thousands of partial derivatives into a single vector that updated each of the model parameters in a single step to make the program’s outputs a bit less wrong. It repeated this “back propagation” thousands of times to “train” the model. I am omitting some details around how the training sets were composed and other mechanics here for purposes of brevity.
It did feel magical each morning, after it had been training all night to give it some new test data and watch it “learn” over time how to identify the digits.
That said, there was no cognition in this system, it was simply a pattern recognition device which happened to accept a multi-dimensional input, which to me as a human represented a number. Particularly in the trained model which was entirely static. It was like pouring water on an uneven surface where the model parameters were the contours of the surface and the input was the water. Of course the contour impacts how the water will flow and where it will pool, but there is no thinking, it’s just physics at work. Even though my program would score an “8” correctly and also suggest that said “8” was more like a “3” than a “1”, it had no concept of what is an 8 or what really was a 3.
To summarize what the deep learning-based models do today is that they take multi-dimensional input and then predict within an output framework where some of the degrees of freedom have been constrained, a best guess of an output that is “least wrong” relative to the data on which they have been trained. You put in X, get out Y. It just happens that X can be text, images, and natural language, and Y similarly can be multi-dimensional and multi-modal.
In the last year, the tooling to package these models and embed them within other computing environments has advanced a lot! As has the ability to specify limited sets of curated data to drive the model's output. This feels even more like a spreadsheet where your input to the model can be thought of as a cell and the function therein and curated data sets can be thought of reference data on other sheets.
Interestingly, the human language interfaces that sit on top of today’s prominent models might mean by definition that model reference data is inherently insecure. One of the most common ways for data to be accessed against the will of an application owner is what are referred to as “code injection” vulnerabilities. Basically this means tricking a computer program into accepting an input that is actually itself code. That malicious code which has been injected can then do funny things like print out underlying reference database tables.
Largely this form of vulnerability is mitigated within the code’s runtime process where, prior to executing an input, a computer program parses the input to understand the commands which it has received. Because software code is structured into valid and invalid inputs, these parsers can then ignore or alert when injected code arrives. In the case of large language models, by definition the input to them is unstructured—it’s English as you and I would speak. As a result, it seems to me that it will be nearly impossible to prevent reference data exfiltration from occurring. Over the long run, this will lead to even private reference data sets increasingly “leaking” from the systems where they run. An implication from this is that for the most powerful applications of these models to be applied, they are likely to be done so within controlled networks where sensitive reference data is already accessible.
Finally, once a model has a level of “base training” complete, those model parameters can be easily packaged and shared. We see this within an increasingly robust open ecosystem of readily available pre-trained models (i.e. they can generally be picked up and customized to a given domain with relatively little compute cost). Given the pace of evolution here, it seems safe to expect continued commoditization of base models and continuously decreasing cost of model deployment.
These three characteristics:
an inherent tendency for reference data leakage
rapidly decreasing base model development costs
a total lack of actual cognition taking place, despite how “aware” these models feel
point to fewer dominant virticalized AI offerings within specific niches and instead a proliferation of hyperlocal “intranet-like” LLM-based computing environments specific to the individuals who built them and the environments in which they were deployed.
Forgive me for sounding repetitive, but this all continues to feel a lot like the expansive spreadsheets from the days of yore that lived on a shared drive and referenced proprietary internal data stores such as Microsoft Access databases and other spreadsheets.
Bringing it all together
So what’s going to happen from here? Personally, I’d avoid making bets on specific LLM-based niche products (and I will caution my angel group to do the same) and instead I’m expecting value to accrue within the leading cloud providers that can allow individuals to more easily wire together their existing environments. I expect Amazon, Microsoft, SalesForce, and Google to continue to make model deployment more frictionlessly possible within “intranet” style corporate environments. I’d expect SalesForce and Microsoft to be the best positioned among this group to benefit.
Separately, it might be a good time to bet on a basket of “old world” industries if you have the capacity to hold for a decade — particularly those with large white collar administrative layers who could see continuous incremental margin expansion as they are able to do more with less. Car insurance comes to mind for example.
Likely there will be a good amount of data infrastructure “cleanup” work that needs to get done in order to make data accessible and usable for local model deployments. I think that bodes well for players like Cognizant, Accenture, Tata, and the like.
In future posts, I’ll dig in more specifically to where I think the most interesting opportunities within healthcare and IT services exists.
If you enjoyed this post, please forward to a friend and encourage them to subscribe.
If you think I got something wrong here, please let me know in the comments below. I write this as much to learn as for any other reason :)
Finally, if you are interested in making healthcare investments through me and my expert colleagues at Nintey5Health let me know. Separately if you are building in next generation care delivery, software as medical device, health data liquidity, or healthcare SaaS, please reach out via LinkedIn or by email.
In conclusion, there is only one superhuman AI and he retired long ago.